Enference represents more than twenty years of experience with the design and realization of digital knowledge systems. In particular with the type of systems we refer to as semantic reference networks.
A semantic reference network is a network of references that is used to link knowledge resources ‑ like text documents, database records, web pages, etcetera ‑ to structures of keywords, thus making information searchable in a highly directed way.

To realize this, the knowledge worker organizes the available digital knowledge, applies meaningful connections, and makes content items searchable. For this he or she is equipped with tools that don't require any technical expertise, only domain knowledge is needed.

Example: Cultural Heritage
The Cultural Heritage Agency of the Netherlands, a service of the Ministry of Education, Culture and Science, wants to improve access to knowledge a much as possible, with the aim of "unburdening". This means: supporting citizens, entrepreneurs, knowledge institutions and governmental organizations with their initiatives, helping with the execution of their tasks, and facilitating the necessary processes.
The motto is "linking", linking of knowledge domains like archaeology, built and movable heritage, cultural landscapes and spatial planning. This is an infrastructural task.
A lot of specialized knowledge is available in all sorts of resources inside and outside the heritage domain. In heritage institutions, in planning departments of municipalities, in the land register, in the Royal Library, the National Archive and the Institute for Sound and Vision. Improving access to that knowledge makes it faster, easier and cheaper for citizens, companies, research institutions, municipalities and financiers to make decisions and developing new initiatives.
This requires an efficient solution: a digital infrastructure that links data from diverse and dispersed sources. The Agency is currently building such a digital infrastructure, with many partners sharing their data and in which information can easily be traced and selected by directed search, resulting in its fast and cheap availability for a broad group of potential users.
To be able to connect the information in the resources via thesauri, an infrastructure is used that exists of three layers.
Together these three layers form the knowledge system. The reference network is composed of the reference layer plus the linked metadata records. It is the central part of the knowledge system. Represented schematically it looks like this:
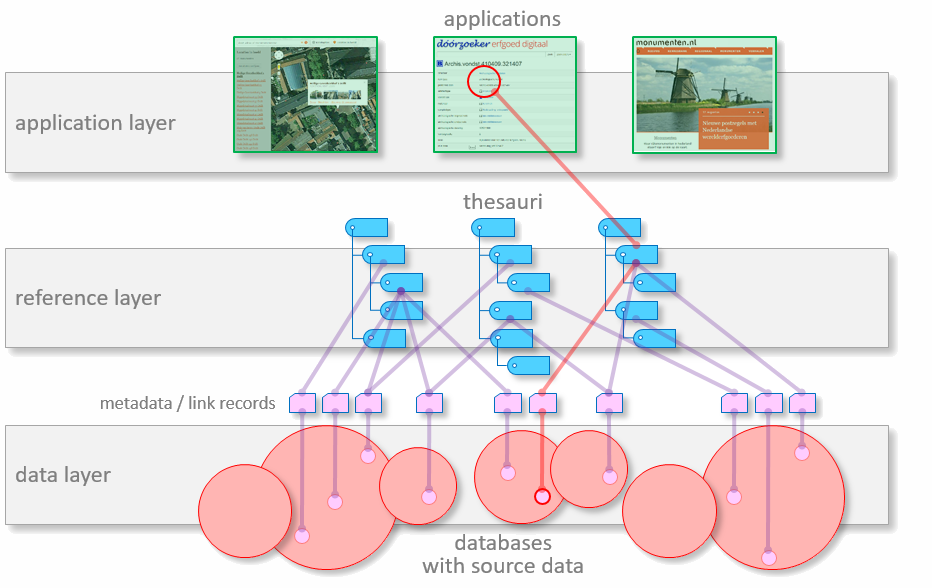
For applications that use the reference network there are basically two ways to retrieve specific information from character based source data: searching for text via keywords, or searching for sets of numbers, like dates or coordinates of locations. The first method is called "semantic search", the second could be called "mathematical search". The two methods also can be combined.
Example: Semantic and mathematical search
During a research about agriculture and livestock in the Middle Ages the question arises where and when chicken farms have emerged.
To find the answer, the researchers make use of databases with archaeological finds. They filter the data by the period "Middle Ages", by the material "animal bone" and by the species "Gallus gallus domesticus" or "chicken, hen, fowl". These terms, respectively, are taken from a thesaurus on periods, a thesaurus on archaeological materials, and a archaeozoological thesaurus.
The set of source data that remains after filtering can be divided into five periods: the Early Middle Ages, that exist of the periods A, B, C and D, and the Late Middle Ages. This division can be done based on the numeric values indicating the start and end of a period, for instance 900-1050. It also can be done by taking the name of a period, for instance "Middle Ages early D", a semantic selection.
Next, for each period the finds are plotted on a map based on the coordinates of their location ‑ a mathematical activity. Each find is rendered as a colored dot, yellow, orange, red or purple, the color representing the amount of bones per find, respectively 1-10, 11-100, 101-1000, and more than 1000 bones.
By observing per period the concentrations of the purple dots (and, possibly, of the red ones), the researchers get an idea where and when chicken farms arose.
In a reference network data are linked semantically, that is, by words. If in a specific domain certain keywords are used again and again, they can be collected for reuse in a list, like an index in a book. And just like with such an index, direct links can be created between the keywords in the list and related words in the source data. This way searching becomes actually more like selecting relevant links, which is much faster then having to start from scratch for each search.
The "related words in the source data" that are mention above exist usually in metadata records. Content items in the data layer are often provided with a separate block of data with information about the item itself: who is the author, what is the creation date, what are keywords that represent the content, etcetera. This kind of "data about data" is called metadata. A record with metadata can be compared with an old-fashioned card from the catalogue of a library.
Example: Metadata
An article from a magazine (digital or on paper) can have the following metadata:
label jansen_c_1986_2 title Eating habits in the Middle Ages author Jansen, C. publication date 1986 published in Cultural Historical Perspective keywords archaeology, archaeozoology, Bovidae, Gallus gallus domesticus, Middle Ages link http://www.rce.org/articles/archaeology/jansen_c_1986
The metadata are gathered in a record, which is linked to both the thesauri (by using their keywords) and to the related content item (file) in the data layer. In the example above, for instance, this link to the source is realized through the hyperlink at the bottom.
Sometimes the metadata are originally already present, but when items without metadata are imported into the data layer, the metadata have to be created explicitly afterwards. If the new items consist mainly of text, constructing the metadata records often can be automated with the help of natural language processing techniques.
The lists with common keywords on the one hand, the metadata records on the other hand, and the connections between these two form the core of the reference layer.
If providing metadata (which data do you use for the "catalogue card", for the record?) is based on pre-established lists of keywords, those lists are called controlled vocabularies. With them, filling the metadata records takes places in a highly structured way, they provide for univocality. Thus findability of items in the data layer can be realized in a rather precise and consistent way.
A next step is to add synonyms, conjugations and language versions to the terms in the controlled vocabularies. Starting with the search term "car", you will then also find content related to "cars", "auto", "automobile", "motor vehicle" and "voiture". A term which is provided with these kind of variants is called a concept.
Example: A concept with language variants and synonyms
The concept "boarded sail" from a thesaurus of windmill parts:
label boarded sail description A mill's sail where a wooden board is used to catch the wind, instead of the common canvas. English name boarded sail English synonym wood-framed sail Dutch name bordwiek Dutch synonym wiek met borden, wiek met bordentuig German name Holzgatterflügel German synonym Türenflügel French name ailes à quarterons French synonym voilure de bois source Dictionary of Molinology
Furthermore, in many cases the description that goes with a concept can be pulled apart in separate derivable properties, which as such can play a distinct role in searches.
Example: A concept with mathematical data
The concept "Early Middle Ages D" from a thesaurus of archeological periods:
label Early Middle Ages D start date 900 end date 1050 description The period from the 5th century (after the disintegration of the Roman Empire) until the mid-10th century. Sub period D covers the last 150 years of this period.
In the last example the start and end date are derived from the description. This type of numeric properties can be used for mathematical search, like filtering all content items that have a date between 500 and 1000 AD.
When finally the concepts are arranged hierarchically ‑ by placing for instance the terms "Early Middle Ages" and "Late Middle Ages" under the term "Middle Ages ‑ the keyword list becomes a thesaurus.
The hierarchy makes it possible to search in a very structured way and thus retrieve much more relevant information than in a simple search. If a certain search term has underlying terms in the hierarchy, then also content linked to those terms will be included in the search result. With the term "Middle Ages" you will also find content that is linked to the terms "Early Middle Ages" and "Late Middle Ages", and possible other terms that exist in that part of the hierarchy.
Example: Thesauri
The thesaurus of archeological periods is structured according to a time-based division into periods.
[...] Middle Ages (450 -1500) Early Middle Ages (450 ‑ 1050) Early Middle Ages A (450 ‑ 525) Early Middle Ages B (525 ‑ 725) Early Middle Ages C (725 ‑ 900) Early Middle Ages D (900 ‑ 1050) Late Middle Ages (1050 ‑ 1500) Late Middle Ages A (1050 ‑ 1250) Late Middle Ages B (1250 ‑ 1500) [...]
The archeozoological thesaurus is structured according to a tight taxonomic classification: a species is placed under a genus, which on its turn is placed under a family.
[...] Bovidae (a large family of ruminants distinguished by their hollow unbranched horns) Bison (genus) Bison priscus (species: bison) Bos (genus) Bos primigenius (species: aurochs) Bos taurus (species: ox) Capra (genus) Capra hircus (species: goat) Ovis (genus) Ovis ammon (species: moufflon) Ovis aries (species: sheep) [...]
A reference network is inhabited by items, it is an item-based findability system. Those items are either a concept ‑ basically a term representing a class of similar objects or phenomena, like "book" or "biology" ‑ or a record representing a real life instance of an object or phenomenon ‑ like the writer or publisher of a specific book.
A record representing a real life instance exists of a set of properties that is selected to realize a desired form of findability. Links to concepts are mostly used for global classification of the instance, while links to other records or to fixed values like numbers or strings of characters give more specific information.
Example: A record representing the book "On the origin of species"
hasLabel On the origin of species hasItemType book hasAuthor Darwin, Charles hasPublisher Murray, John hasPublicationDate 1859
The example above is a record with some data about a real life object that is typified as a "book" by the reference to the corresponding concept "book". Also reference is made to a record about a person "Darwin, Charles" and to another record about a person "Murray, John". These three items are shown in the examples below.
Example: The concept "book"
hasLabel book hasItemType concept hasDescription A long written work that can be read from a stack of sheets of paper or on an electronic device.
Example: A record representing the person "Darwin, Charles"
hasLabel Darwin, Charles hasItemType person hasDate 1809-02-12 / 1882-04-19 isAuthorOf On the origin of species
Example: A record representing the person "Murray, John"
hasLabel Murray, John hasItemType person hasDate 1808 / 1892 isPublisherOf On the origin of species
As you can see in the example of the record representing the book "On the origin of species", the links to the persons "Darwin, Charles" and "Murray, John" are typified as a "hasAuthor link" and a "hasPublisher link". From this you ‑ and software ‑ can easily infer that Charles Darwin is the author of the book and John Murray the publisher. Likewise you can infer that the fixed numeric value "1859" indicates the year of publication.
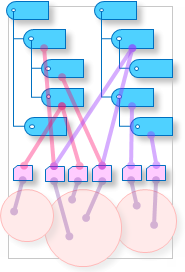
Usually different types of reference (links with a different name) point to keywords in different thesauri. For instance, the reference type "hasMaterial" will be linked to keywords in a thesaurus of materials, while the reference type "hasPeriod" will point to keywords in a thesaurus of periods. Also reference can be made to a record rather than to a concept (keyword) in a thesaurus: the reference type "hasAuthor" points to a record of the person Charles Darwin, a "real life object".
These named references like "hasAuthor", "hasPublisher", "hasPublicationDate", and so forth, can make your search very focused. If you want to collect all records in a certain knowledge system about books written by Charles Darwin, you simply select the item type "book" and the reference named "hasAuthor" with the value "Darwin, Charles" (or "Charles Darwin"). Provided that the knowledge system is well maintained, these three choices will give you exactly what you asked for, nothing less and nothing more.
The model has been applied in different projects over the last couple of years (see below). It can be described as a "simple model for authoring of item-based reference networks".
